
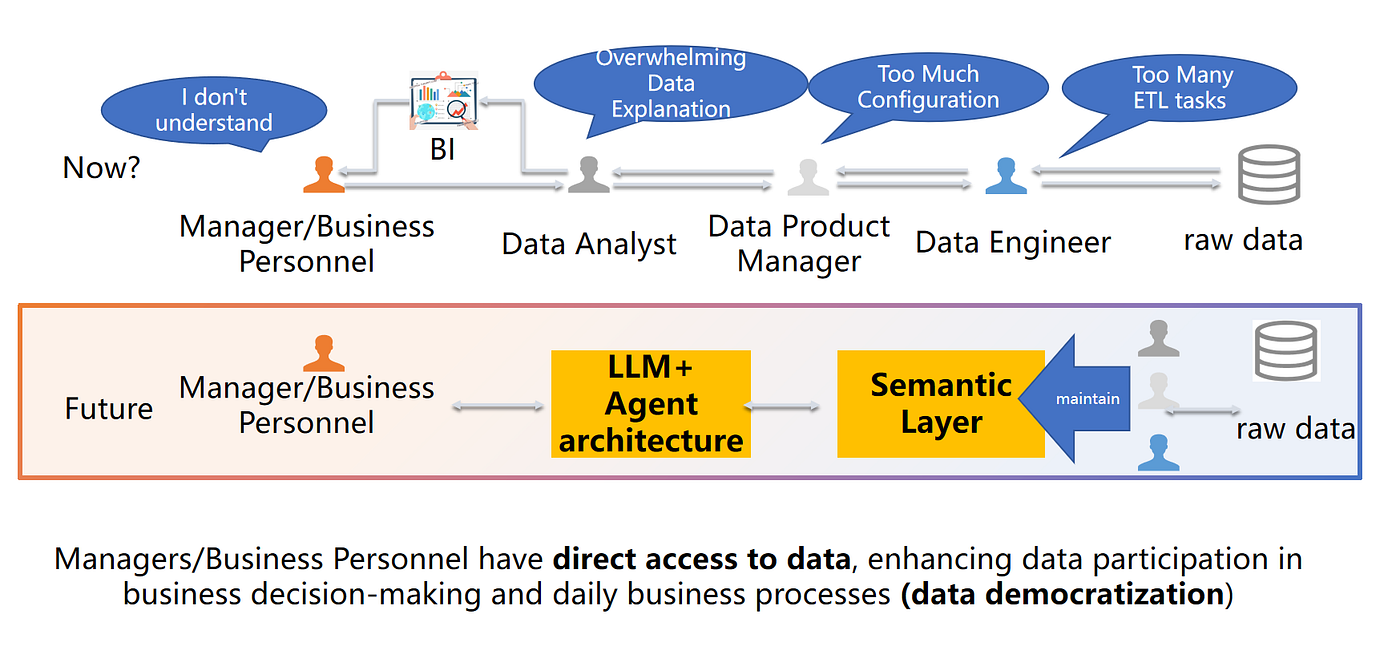
Los equipos de datos empresariales no carecen de herramientas — carecen de accesibilidad que se mantenga correcta.
La mayoría de las organizaciones aún tienen una división familiar:
- Un pequeño grupo de analistas puede explorar datos con confianza
- Todos los demás esperan en una cola para obtener respuestas, paneles o exportaciones
El análisis de datos basado en agentes es un camino práctico para salir de ese cuello de botella, pero solo si se construye sobre la base correcta.
Este artículo explica la idea central y la arquitectura que la hace confiable: arquitectura de agente + una capa semántica.
Introducción: La crisis de accesibilidad a los datos
Las empresas recolectan más datos que nunca, pero la mayoría de los empleados no pueden usarlos en el día a día.
El modo de fallo común no es "a la gente no le importa". Es este flujo de trabajo:
- Un gerente hace una pregunta
- La pregunta rebota entre herramientas, paneles, analistas e ingeniería
- La definición de la métrica cambia en medio del hilo
- La respuesta llega demasiado tarde para importar
El análisis basado en agentes apunta a la arquitectura detrás de ese dolor: reduce las transferencias mientras mantiene intactos el significado comercial y la gobernanza.
¿Qué es el análisis de datos basado en agentes?
El análisis de datos basado en agentes no es "un chatbot que escribe SQL".
Es un sistema de IA que puede planificar, ejecutar, validar e iterar a través de análisis de múltiples pasos mientras se mantiene anclado en las definiciones de su organización.
A alto nivel, un analista basado en agentes debería poder:
- Comprender la intención comercial (no solo la sintaxis de la consulta)
- Descomponer preguntas complejas en tareas analíticas más pequeñas
- Usar definiciones comerciales gobernadas (métricas, dimensiones, reglas)
- Validar resultados y manejar casos extremos
- Mantener el contexto en preguntas de seguimiento ("desglose eso por región")
Quién se beneficia: El problema de "Amanda"
Considere a un gerente preguntando:
"¿Cuál es el ingreso mensual por región, sucursal y tipo de producto hasta septiembre de 2024? ¿Estamos en camino o fuera del camino respecto al objetivo?"
Esa "única pregunta" típicamente se convierte en una cadena de solicitudes:
- Aclarar qué datos existen y dónde viven
- Alinearse en las definiciones de métricas (¿qué cuenta como ingreso?)
- Investigar anomalías
- Convertir los resultados en un informe compartible
- Configurar monitoreo o alertas para el futuro
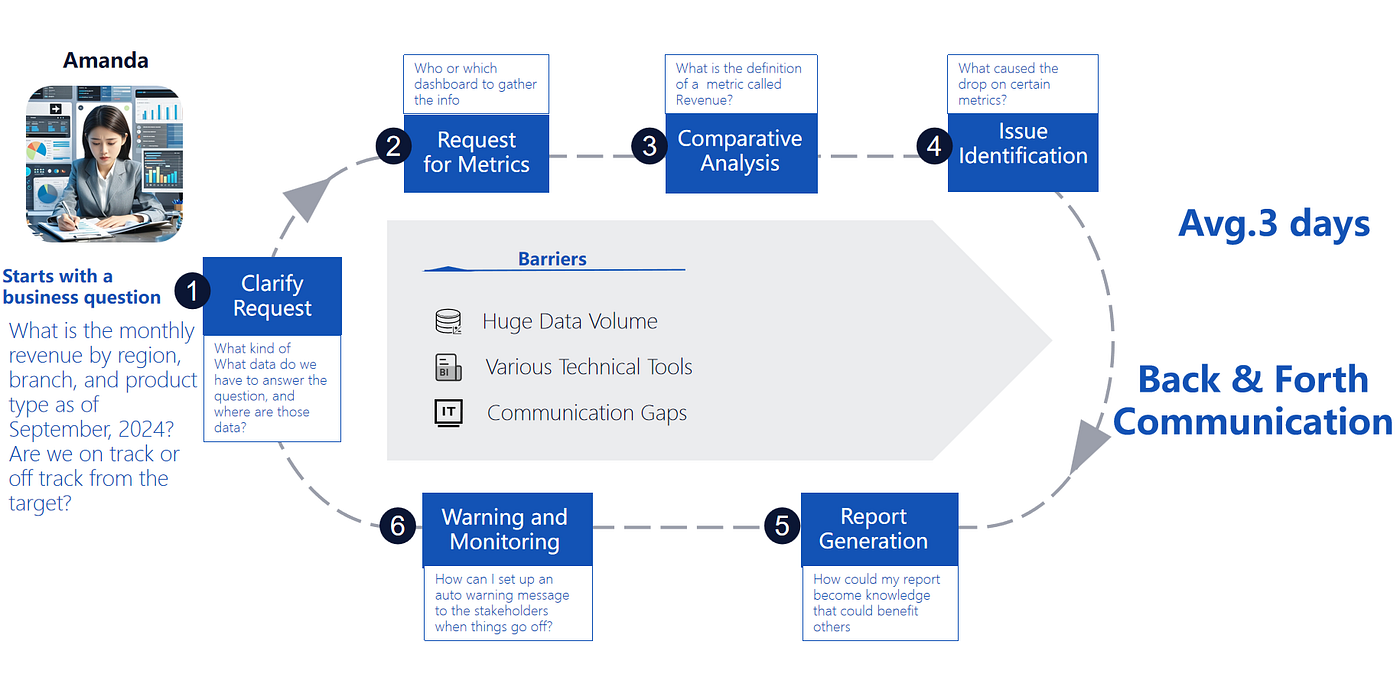
El análisis basado en agentes elimina el ir y venir al permitir que los usuarios de negocio pregunten directamente — mientras el sistema maneja las partes difíciles detrás de escena.
Las tres eras del análisis de datos
Ayuda ver el análisis basado en agentes como una evolución, no como un reemplazo.

Era 1: La era de Excel
- Consumidores de datos: ~1%
- Valor liberado: "Qué" (descriptivo básico)
- Herramientas: hojas de cálculo y flujos de trabajo manuales
Era 2: La era de BI
- Consumidores de datos: ~10%
- Valor liberado: "Qué y Por qué" (descriptivo + diagnóstico)
- Herramientas: paneles, filtros y capas de visualización
Era 3: La era de la conversación con IA
- Consumidores de datos: 90%+
- Valor liberado: "Qué, Por qué y Cómo" (incluyendo prescriptivo)
- Herramientas: BI + IA, donde el análisis es guiado por conversación
La promesa es real — pero la confiabilidad es la barrera.
Por qué los LLM por sí solos no ofrecen análisis empresariales confiables
En entornos empresariales, el enfoque directo de "lenguaje natural → SQL" falla de maneras predecibles:
- Falta de contexto comercial: "Ingreso" puede significar cinco cosas diferentes.
- Esquemas opacos: Los nombres de las columnas rara vez se explican por sí mismos.
- Complejidad de joins: Los almacenes tienen cientos de tablas con lógica de joins frágil.
- Reglas incrustadas: Las transformaciones y exclusiones viven en el código, no en los nombres de la base de datos.
Esta es la razón por la cual las organizaciones obtienen respuestas que parecen seguras pero son incorrectas.
La capa semántica: El fundamento de la confiabilidad
Una capa semántica se sitúa entre los usuarios finales (y la IA) y los sistemas de datos en bruto, mapeando conceptos comerciales a implementaciones técnicas.
Convierte:
- "Ingreso" en una definición de métrica gobernada
- "Cliente activo" en una regla consistente
- "Región" en el mapeo de dimensión correcto
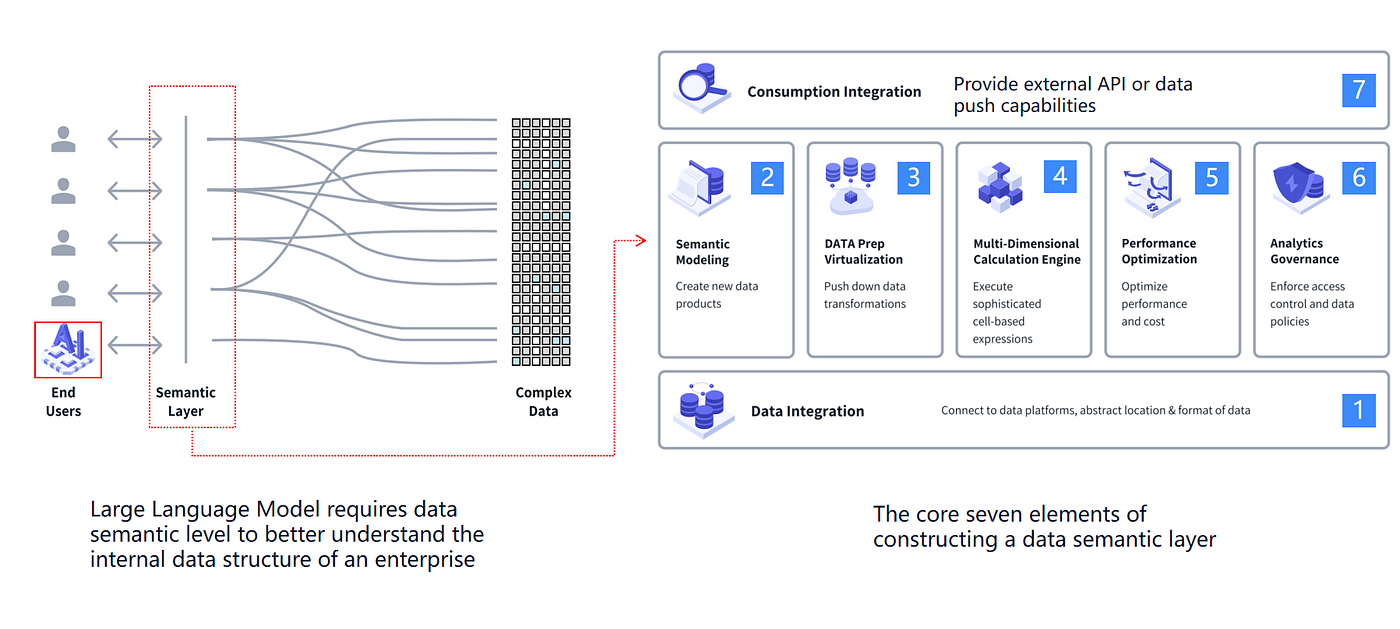
Los elementos centrales de una capa semántica sólida
Aunque las implementaciones varían, la mayoría de las capas semánticas empresariales necesitan:
- Integración de datos a través de plataformas
- Modelado semántico (métricas + dimensiones que coincidan con conceptos comerciales)
- Virtualización / pushdown de transformaciones
- Un motor de cálculo para lógica de métricas consistente
- Optimización del rendimiento
- Gobernanza (RBAC, políticas, manejo de PII)
- Integración de consumo (APIs, herramientas de BI, casos de uso integrados)
Ontología + capa semántica: Haciendo que el significado sea legible por máquina
En sistemas de datos, una ontología define:
- Entidades (clientes, pedidos, transacciones)
- Atributos (fecha, monto, estado)
- Relaciones (los pedidos contienen productos)
- Reglas (restricciones y lógica)
Una capa semántica es a menudo la forma más práctica de implementar esa ontología para análisis.
Cuando las métricas y dimensiones están codificadas, los agentes pueden hacer razonamiento semántico:
- desambiguar términos ("ingreso bruto vs. neto")
- inferir agrupaciones ("clientes premium")
- mantener definiciones consistentes entre equipos
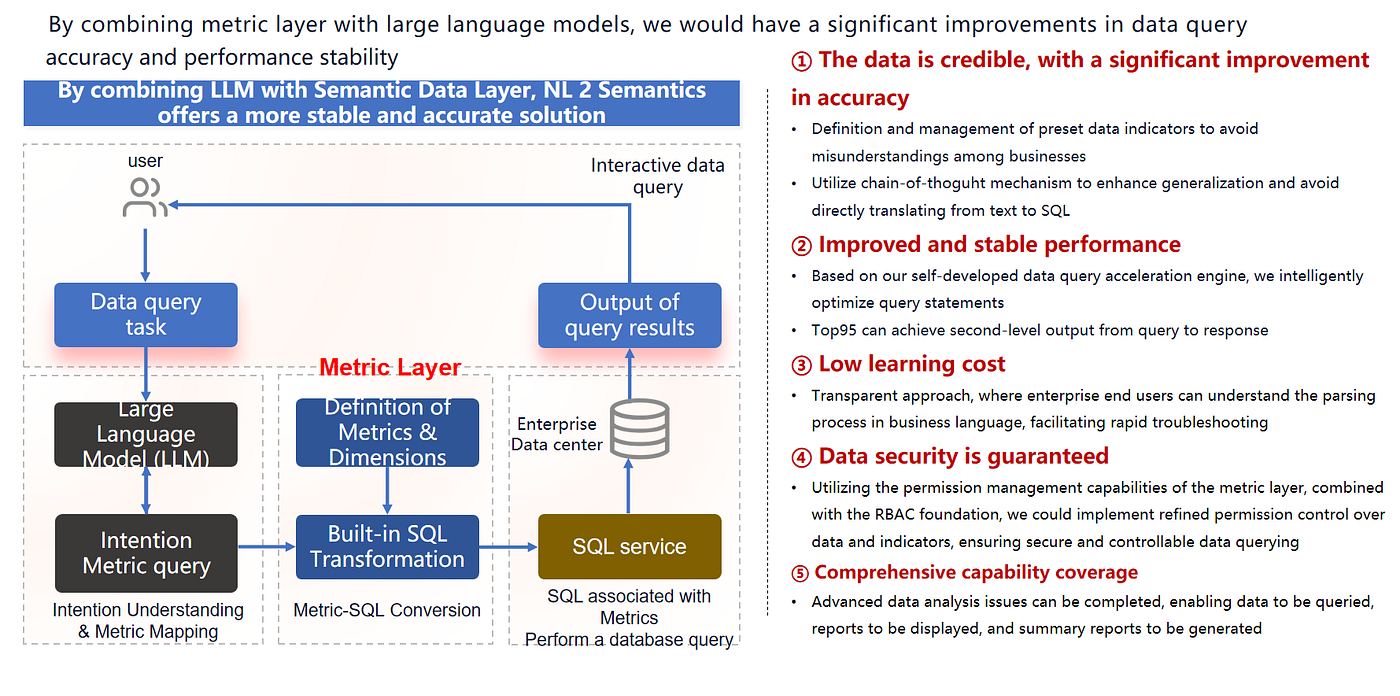
Por qué la arquitectura de agente + capa semántica supera al LLM-to-SQL puro
En lugar de pedirle a un LLM que genere SQL en bruto, el flujo mejor es:
- Interpretar la intención
- Mapear a métricas/dimensiones gobernadas en la capa semántica
- Usar transformaciones validadas (SQL de capa de métricas)
- Ejecutar a través de un servicio de consultas controlado
- Devolver resultados que sean explorables mediante seguimientos
Modos de fallo comunes que esto evita
- Alucinaciones de esquema (tablas que no existen)
- Joins incorrectos (especialmente de múltiples saltos y auto-referenciales)
- Desviación de la lógica de negocio (filtros incorrectos, exclusiones faltantes)
- Desastres de rendimiento de consultas (escaneos completos de tablas)
- Puntos ciegos de seguridad (permisos, exposición de PII)
Por qué funciona mejor en la práctica
La combinación proporciona:
- Credibilidad: definiciones de métricas compartidas reducen debates entre equipos
- Rendimiento estable: planes de consulta optimizados y reutilizables
- Menor costo de aprendizaje: los usuarios pueden ver cómo se mapeó la intención a métricas
- Seguridad: RBAC y gobernanza se aplican en la capa semántica
- Flujos de trabajo de extremo a extremo: consultar → visualizar → resumir → compartir → monitorear
Guía práctica para equipos que adoptan análisis basado en agentes
Si está construyendo (o comprando) una plataforma de análisis basada en agentes, comience aquí:
1) Invierta en la capa semántica primero
Defina métricas y dimensiones con las partes interesadas del negocio. La IA no puede arreglar un significado no definido.
2) Prefiera agentes reales sobre envolturas de "chatea con tus datos"
La planificación de múltiples pasos, validación y ejecución gobernada no son opcionales a escala empresarial.
3) Planifique la iteración continua
Las definiciones semánticas evolucionan a medida que su negocio cambia. Trátelas como productos.
4) Mida resultados que importan
- ¿Coincide el resultado con lo que produciría un buen analista?
- ¿Cuánto disminuyó el tiempo de ciclo?
- ¿Cuántos usuarios se volvieron autoservicio?
- ¿Cuántos mensajes de analistas de "explica este panel" desaparecieron?
Conclusión: La democratización de los datos es finalmente práctica
El objetivo no es reemplazar a los analistas. Es extender su impacto:
- Los analistas codifican definiciones y gobernanza
- Los agentes hacen que esas definiciones sean accesibles para todos
Cuando los usuarios de negocio pueden preguntar e iterar de manera segura — con la capa semántica manteniendo las respuestas ancladas — los datos dejan de ser un cuello de botella y comienzan a ser una ventaja competitiva.
Conclusiones clave
- El LLM-to-SQL directo falla en esquemas, joins, reglas de negocio, rendimiento y seguridad.
- Una capa semántica proporciona el significado, la gobernanza y la consistencia que la IA necesita.
- La arquitectura de agente convierte preguntas en análisis validados de múltiples pasos.
- Juntos, permiten una inteligencia empresarial confiable con IA para el 90%, no solo para el 10%.