
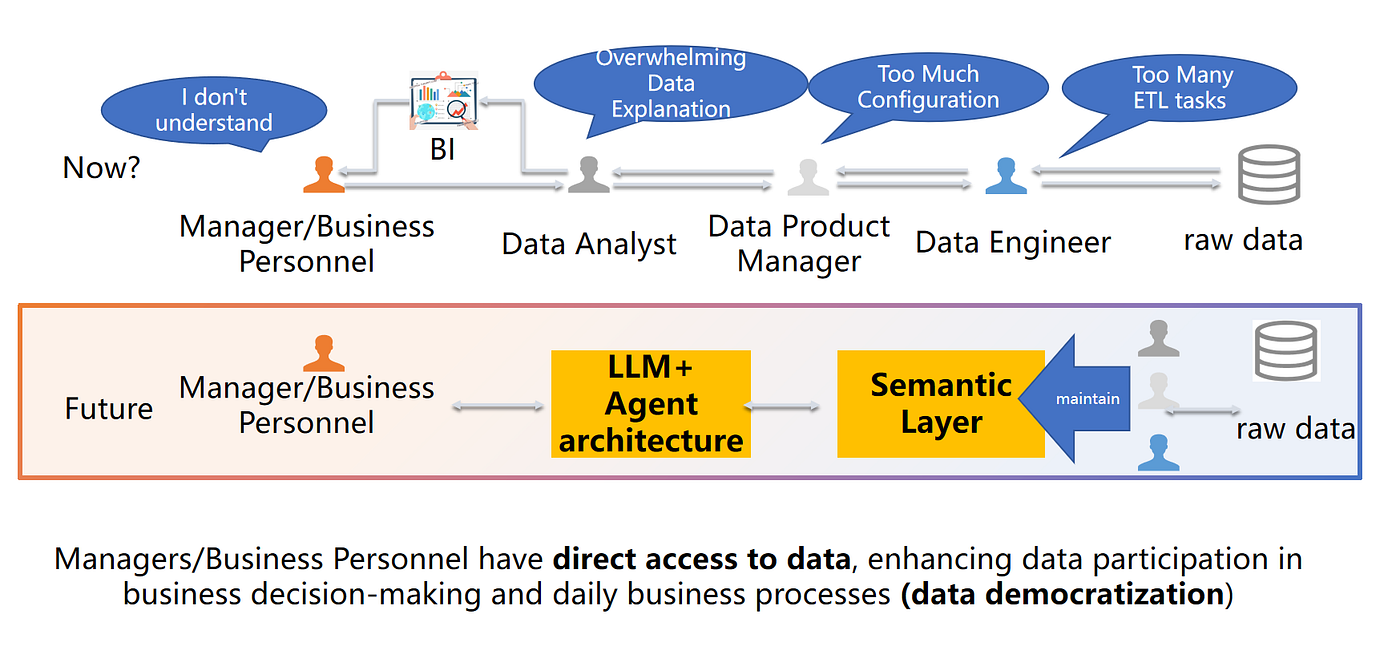
エンタープライズのデータチームに不足しているのはツールではありません — 「正しさを維持できるアクセシビリティ」です。
ほとんどの組織には、おなじみの分断が依然として存在します:
- 少数のアナリストだけが自信を持ってデータを探索できる
- それ以外の全員が、回答、ダッシュボード、エクスポートを求めてキューで待つ
エージェンティックデータ分析は、このボトルネックを解消する実用的な道筋ですが、それは正しい基盤の上に構築された場合に限ります。
この記事では、中核となるアイデアと、それを信頼性のあるものにするアーキテクチャを説明します:エージェントアーキテクチャ+セマンティックレイヤー。
はじめに:データアクセシビリティの危機
企業はかつてないほど多くのデータを収集していますが、ほとんどの従業員はそれを日常的に活用できていません。
よくある失敗パターンは「人々が関心を持っていない」ではありません。それは次のようなワークフローです:
- マネージャーが質問する
- 質問がツール、ダッシュボード、アナリスト、エンジニアリングの間を跳ね回る
- メトリクスの定義がスレッドの途中で変わる
- 回答は遅すぎて意味をなさない
エージェンティック分析は、この問題の背後にあるアーキテクチャをターゲットにしています:ビジネス上の意味とガバナンスをそのまま維持しながら、ハンドオフを削減します。
エージェンティックデータ分析とは何か?
エージェンティックデータ分析は「SQLを書くチャットボット」ではありません。
それは、組織の定義に基づきながら、計画、実行、検証、反復を多段階の分析を通じて行えるAIシステムです。
高いレベルでは、エージェンティックアナリストは以下ができるべきです:
- ビジネスの意図を理解する(クエリ構文だけでなく)
- 複雑な質問をより小さな分析タスクに分解する
- ガバナンスの効いたビジネス定義(メトリクス、ディメンション、ルール)を使用する
- 結果を検証し、エッジケースを処理する
- フォローアップ間でコンテキストを引き継ぐ(「それを地域別に分解して」)
誰が恩恵を受けるか:「アマンダ」問題
次のように質問するマネージャーを考えてみましょう:
「2024年9月現在の月次収益を地域、支店、製品タイプ別に教えてください。目標に対して順調ですか、それとも遅れていますか?」
この「一つの質問」は、典型的には一連のリクエストになります:
- どのデータがどこに存在するかを明確にする
- メトリクスの定義(何を収益とみなすか)を調整する
- 異常値を調査する
- 結果を共有可能なレポートに変換する
- 将来のための監視やアラートを設定する
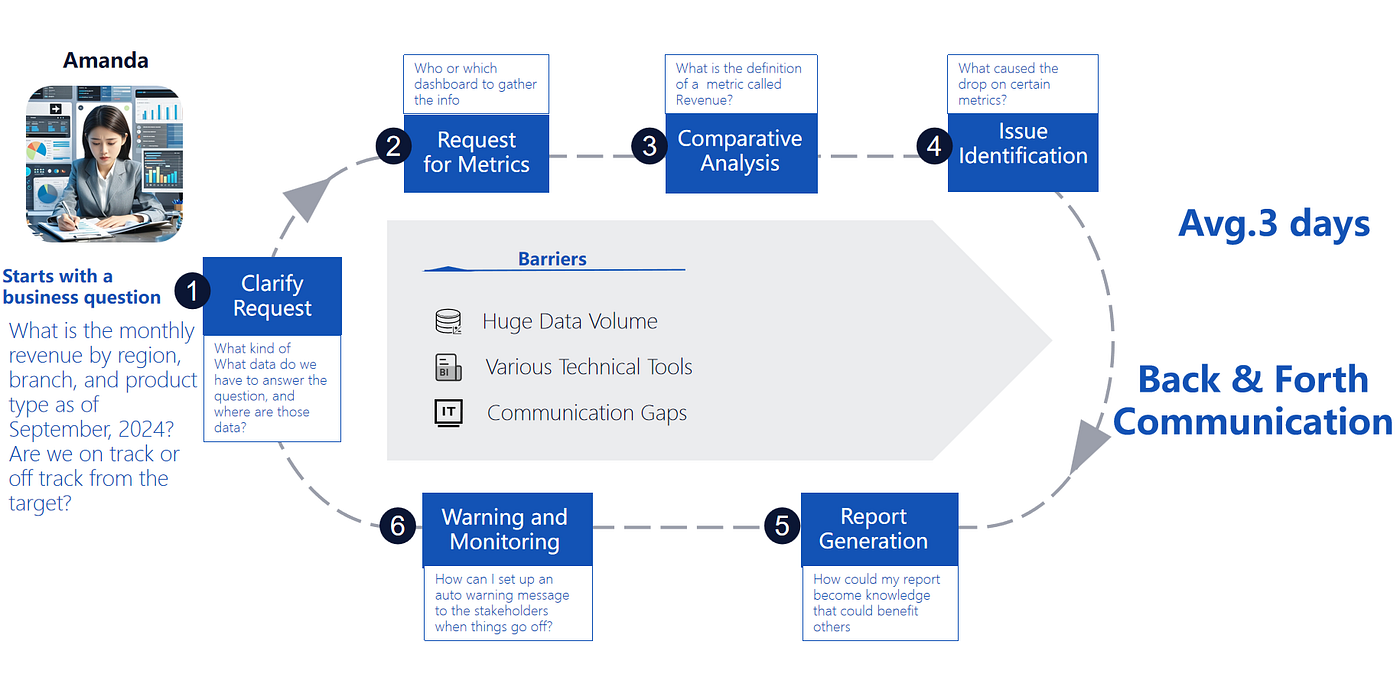
エージェンティック分析は、ビジネスユーザーが直接質問できるようにすることで、この行き来を排除します — 一方、システムは舞台裏で難しい部分を処理します。
データ分析の3つの時代
エージェンティック分析を、置き換えではなく進化として捉えることが役立ちます。

時代1:Excelの時代
- データ消費者:約1%
- 引き出された価値:「何が」(基本的な記述)
- ツール:スプレッドシートと手動ワークフロー
時代2:BIの時代
- データ消費者:約10%
- 引き出された価値:「何が&なぜ」(記述+診断)
- ツール:ダッシュボード、フィルター、可視化レイヤー
時代3:AI会話の時代
- データ消費者:90%以上
- 引き出された価値:「何が、なぜ、どのように」(処方的なものを含む)
- ツール:BI+AI。ここでは分析が会話によって導かれる
約束は現実的です — しかし信頼性が障壁です。
LLMだけでは信頼性の高いエンタープライズ分析を提供できない理由
エンタープライズ環境では、直接的な「自然言語 → SQL」アプローチは予測可能な方法で失敗します:
- 欠落したビジネスコンテキスト:「収益」は5つの異なる意味を持ちうる。
- 不透明なスキーマ:カラム名が自らを説明することはめったにない。
- 結合の複雑さ:データウェアハウスには何百ものテーブルと壊れやすい結合ロジックがある。
- 埋め込まれたルール:変換や除外はコードの中にあり、データベース名にはない。
これが、組織が自信ありげに見えて誤った回答を得る理由です。
セマンティックレイヤー:信頼性の基盤
セマンティックレイヤーは、エンドユーザー(およびAI)と生のデータシステムの間に位置し、ビジネスコンセプトを技術的な実装にマッピングします。
それは以下を変換します:
- 「収益」をガバナンスの効いたメトリクス定義に
- 「アクティブ顧客」を一貫したルールに
- 「地域」を正しいディメンションマッピングに
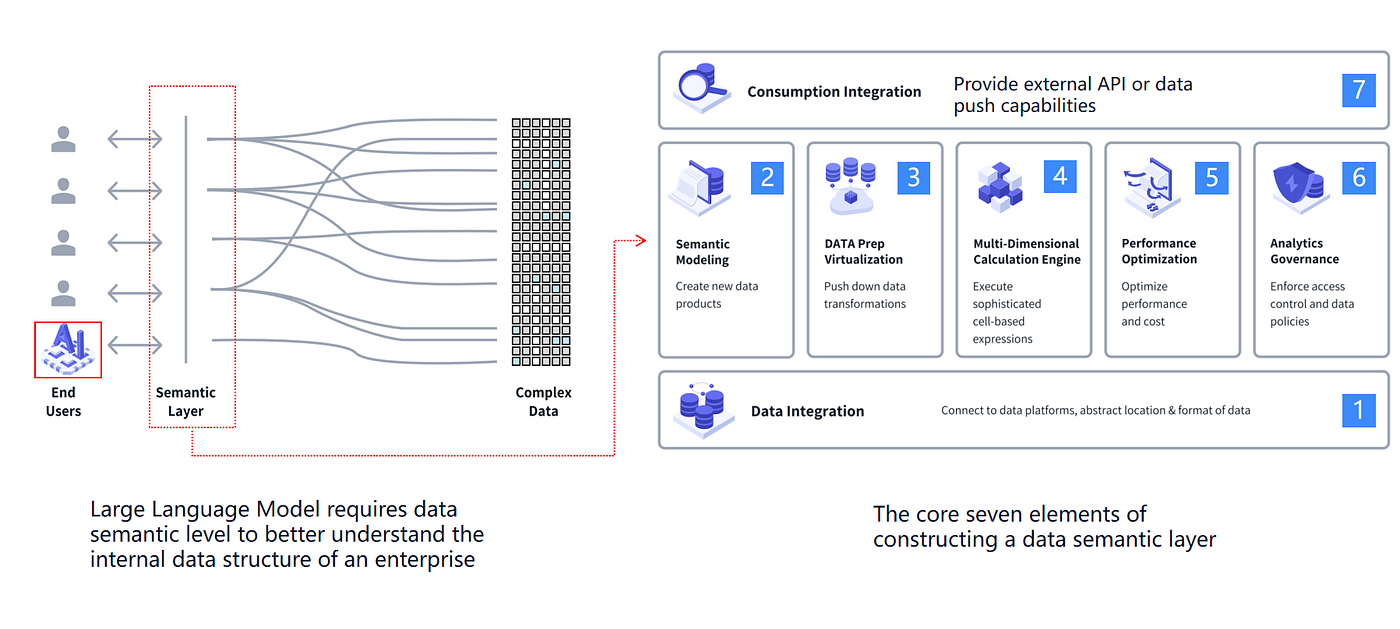
強固なセマンティックレイヤーの中核要素
実装はさまざまですが、ほとんどのエンタープライズ向けセマンティックレイヤーには以下が必要です:
- プラットフォーム間でのデータ統合
- セマンティックモデリング(ビジネスコンセプトに一致するメトリクス+ディメンション)
- 変換の仮想化/プッシュダウン
- 一貫したメトリクスロジックのための計算エンジン
- パフォーマンス最適化
- ガバナンス(RBAC、ポリシー、個人情報の処理)
- コンシューマー統合(API、BIツール、埋め込みユースケース)
オントロジー+セマンティックレイヤー:意味を機械可読にする
データシステムにおいて、オントロジーは以下を定義します:
- エンティティ(顧客、注文、トランザクション)
- 属性(日付、金額、ステータス)
- 関係(注文は製品を含む)
- ルール(制約とロジック)
セマンティックレイヤーは、多くの場合、分析のためにそのオントロジーを実装する最も実用的な方法です。
メトリクスとディメンションがコード化されると、エージェントはセマンティック推論を行えます:
- 用語の曖昧性を解消する(「総収益対純収益」)
- グループ化を推論する(「プレミアム顧客」)
- チーム間で定義の一貫性を保つ
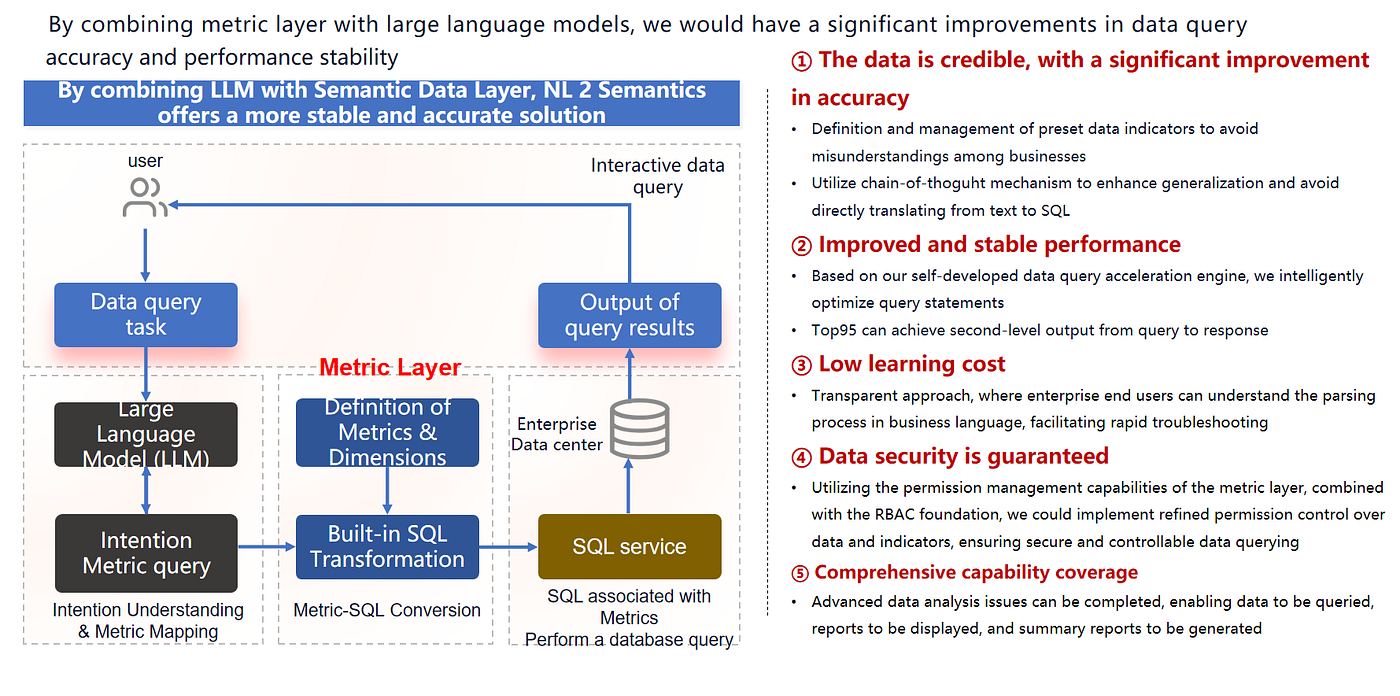
エージェントアーキテクチャ+セマンティックレイヤーが純粋なLLM to SQLより優れている理由
LLMに生のSQLを生成させる代わりに、より優れたフローは次のとおりです:
- 意図を解釈する
- セマンティックレイヤー内のガバナンスの効いたメトリクス/ディメンションにマッピングする
- 検証済みの変換(メトリックレイヤーSQL)を使用する
- 制御されたクエリサービスを通じて実行する
- フォローアップによって探索可能な結果を返す
これによって回避される一般的な障害モード
- スキーマの幻覚(存在しないテーブル)
- 誤った結合(特にマルチホップおよび自己参照)
- ビジネスロジックの逸脱(誤ったフィルター、欠落した除外)
- クエリパフォーマンスの大惨事(全表スキャン)
- セキュリティの盲点(権限、個人情報の露出)
なぜ実際により良く機能するか
この組み合わせは以下を提供します:
- 信頼性:共有されたメトリクス定義がチーム間の議論を減らす
- 安定したパフォーマンス:最適化され再利用可能なクエリプラン
- 低い学習コスト:ユーザーは意図がどのようにメトリクスにマッピングされたかを見ることができる
- セキュリティ:RBACとガバナンスがセマンティックレイヤーで適用される
- エンドツーエンドのワークフロー:クエリ → 可視化 → 要約 → 共有 → 監視
エージェンティック分析を採用するチームへの実践的ガイダンス
エージェンティック分析プラットフォームを構築(または購入)している場合は、ここから始めてください:
1) 最初にセマンティックレイヤーに投資する
ビジネス関係者と一緒にメトリクスとディメンションを定義します。AIは未定義の意味を修正できません。
2) 「データとチャット」ラッパーよりも真のエージェントを優先する
エンタープライズスケールでは、多段階の計画、検証、ガバナンスの効いた実行はオプションではありません。
3) 継続的な反復を計画する
セマンティック定義はビジネスの変化に応じて進化します。それらを製品として扱います。
4) 重要な結果を測定する
- 結果は優秀なアナリストが生成するものと一致していますか?
- サイクルタイムはどれだけ短縮されましたか?
- 何人のユーザーがセルフサービスになりましたか?
- 「このダッシュボードを説明して」というアナリストへのpingはどれだけ減りましたか?
結論:データの民主化はついに実用的になった
目標はアナリストを置き換えることではありません。それは彼らの影響力を拡大することです:
- アナリストは定義とガバナンスをコード化する
- エージェントはそれらの定義を誰もがアクセスできるようにする
ビジネスユーザーが安全に質問し反復でき、セマンティックレイヤーが回答を確かなものにしているとき、データはボトルネックではなくなり、競争上の優位性になり始めます。
重要なポイント
- 直接的なLLM to SQLは、スキーマ、結合、ビジネスルール、パフォーマンス、セキュリティで失敗します。
- セマンティックレイヤーは、AIが必要とする意味、ガバナンス、一貫性を提供します。
- エージェントアーキテクチャは質問を多段階で検証された分析に変えます。
- これらが組み合わさることで、10%だけでなく90%のための信頼性の高いAIビジネスインテリジェンスを可能にします。